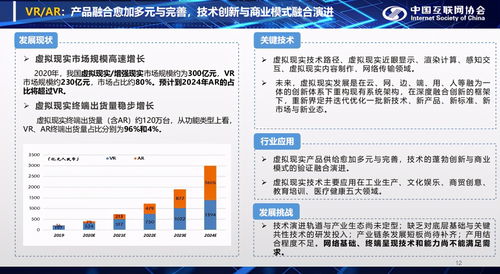
隨著社交媒體的快速發展,微博等平臺已成為信息傳播的重要渠道。海量的微博數據也為信息管理帶來了挑戰。本文基于計算機畢業設計源碼85633,探討了基于爬蟲技術的網絡空間微博信息管理系統的設計與實現,旨在提升網絡與信息安全軟件的開發水平。系統設計主要包括數據采集、信息處理、安全存儲和用戶管理四大模塊。
數據采集模塊通過高效的網絡爬蟲技術,實現對微博平臺信息的實時抓取與更新。爬蟲程序采用多線程和代理IP技術,確保數據的全面性和合法性,同時避免因頻繁訪問而被平臺封禁。數據抓取后,系統對原始信息進行清洗和去重,提取關鍵字段如發布時間、用戶ID和內容文本。
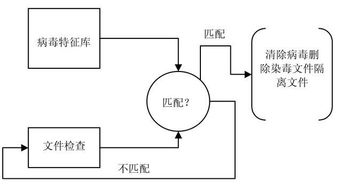
信息處理模塊利用自然語言處理算法,對微博內容進行情感分析、熱點識別和關鍵詞提取。該模塊支持自定義過濾規則,有效屏蔽惡意信息或敏感內容,增強系統的信息安全管理能力。處理后的數據被分類存儲至數據庫,便于后續查詢與分析。
安全存儲模塊采用加密技術和訪問控制機制,確保用戶數據隱私和系統抗攻擊性。數據庫設計遵循規范化原則,支持快速檢索與備份恢復,防止數據丟失或泄露。同時,系統集成日志監控功能,實時記錄操作行為,及時發現異常活動。
用戶管理模塊提供友好的Web界面,支持管理員對系統參數、用戶權限和數據報表的配置。普通用戶可通過權限認證,訪問經過處理的安全信息,實現信息的有效利用。系統還支持API接口,便于與其他安全軟件集成,擴展應用場景。
在實現過程中,我們參考了計算機畢業設計源碼85633,采用Python作為主要開發語言,結合Scrapy框架構建爬蟲組件,使用MySQL進行數據存儲,并引入Django框架開發后臺管理系統。測試結果表明,該系統能夠高效、穩定地管理微博信息,同時滿足網絡與信息安全的要求。
本系統通過爬蟲技術與信息安全措施的結合,為微博信息管理提供了可靠解決方案。未來,可進一步引入人工智能技術,優化信息分析能力,并擴展至其他社交媒體平臺,以應對日益復雜的網絡環境挑戰。